NFV – Compute Concepts
NVF is consist of Compute, Storage and Networking functions. In this post, we will discuss some definitions/ Concepts related to compute function of NFV.
- Host: A host is a server configured with an OS and assigned with a network layer address. In a E2E NFV system, the blade server with the OpenStack roles is the host, and is also called a node. Those with control and management roles deployed are called controller nodes, and those with compute roles are compute nodes.
- Controller Nodes: Controller nodes are hosts on which the sys-server, controller, and measure roles of OpenStack are rolled out. FusionSphere OpenStack OM, MANO VMs are deployed on these nodes.
- Compute Nodes: Compute nodes are the hosts on which the compute roles of OpenStack are rolled out. VNF VMs are deployed on these nodes.
- Management and Compute Groups: Management groups are host groups which consist of controller nodes, while compute groups are those consisting of compute nodes.
- CPU: A CPU, also called a processor or physical CPU, is the electronic circuitry that responds to and processes the basic instructions that drive a computer. The four primary functions of a processor are fetch, decode, execute and writeback. Hyperthreading technology enables a CPU to behave like two logical CPUs, so a CPU can run two independent applications at the same time. To avoid confusion between logical and physical CPUs, Intel also refers to a physical CPU as a socket.
- Cores: Cores, also called CPU cores, physical CPU cores, or physical cores, are data processing units on CPUs. Usually a CPU has 12 cores.
- NUMA: Non-uniform memory access (NUMA) is a method of configuring a cluster of microprocessors in a multiprocessing system so that they can share memory locally, improving performance and making the system easier to expand. Each of these clusters is a NUMA node. Each blade or server usually has multiple CPUs of which each has its own memory resources and may be bonded with I/O devices. In the CloudCore solution, a NUMA node refers to a CPU and its associated memory and I/O devices. Detailed information about NUMA is available here.
- Hyperthreading: Intel’s hyperthreading technology allows a single physical core to act like two separate logical cores to the OS and programs.Hyperthreading performance improvements are highly dependent on applications. For a compute-intensive application on hyper threaded cores, the performance is nearly double than that of non-hyperthreaded cores. However, hyperthreading may degrade the performance of some applications because many processor resources, such as the cache, are shh if the CPU overcommitment ratio is configured.
- Affinity/Anti-affinity: An affinity rule is a setting that establishes a relationship between VMs and hosts. Affinity and anti-affinity rules tell the hypervisor to keep virtual entities together or separated.
-
- NUMA affinity: Two VMs must be deployed on one NUMA node for better performance.
- VM anti-affinity: Two VMs must be deployed on separate hosts for better reliability.
-
- CPU Pinning: Ideally virtualization enables VMs to use all vCPUs available. By default, all VMs share a vCPU resource pool, meaning, multiple threads execute on the same logical CPU cores. Each logical CPU core schedules a vCPU queue to allocate vCPUs as needed. The system preferentially assigns vCPUs to heavily loaded VMs, instead of guaranteeing the performance of individual VMs. You can override this by using CPU pinning. CPU pinning enables you to pin, or establish a mapping between a virtual CPU and a physical core so that the vCPU can always run on the same physical core. This improves the performance of VMs, especially those running important services.
- Interrupt-Core Binding: Interrupt-core binding means designating the physical cores on the management hosts to handle the NIC interrupts, preventing the CPU cores which provide vCPUs to VMs on compute hosts from being affected. After enabling this function, you can configure the following interrupt-core binding policies:
-
- Affinity-based: binds interrupts on the host to vCPUs of IaaS services.
- Anti-affinity-based: binds interrupts on the host to vCPUs of non-IaaS services. You can specify the number of vCPUs based on the given range.
-
- Queue Depth: Queue depth is the number of I/O requests (SCSI commands) that can be queued at a time on a storage controller. The queued requests are then sent to hard disks. Typically, a higher queue depth contributes to better performance. However, if the storage controller’s maximum queue depth is reached, that storage controller rejects incoming commands. When EVS is used, the queue depth affects the performance of different service traffic models to various extents. A queue depth that is too shallow is less resistant to interferences and may cause pulse packet loss. You are advised to retain the default queue depth, 1024, for those received or sent by a NIC.
- Open vSwitch (OVS): OVS is standard OpenFlow technology. It can be implemented by both kernel and user space processes on Linux:
-
- The kernel processes receive packets, match them with flow tables based on the OpenFlow specification, then it processes, and forwards these packets.
- The user space processes configure and maintain commands.
-
- Elastic Virtual Switch (EVS): The EVS is Huawei-developed technology which inherits OVS technology but provides enhanced I/O performance. The EVS can:
-
- Be deployed in the user space of the host OS, the EVS efficiently processes packets by using Intel® DPDK.
- Forward data in user space, decreasing system overhead caused by switches between the kernel and user space processes.
-
- Intel® DPDK: The DPDK is a set of data plane libraries and network interface controller drivers. It provides a simple, complete framework for fast packet processing in data plane applications. The DPDK:
-
- Implements pipeline and run-to-completion models for the fastest possible forwarding on the data plane.
- Includes Poll Mode Drivers (PMDs) which are designed to work without asynchronous, interrupt-based signaling mechanisms, greatly reducing the CPU usage and speeding up packet processing.
-
- Data Center (DC): A data center (DC) is a pool of compute, network, and storage resources available for users to deploy applications. A DC is a geographic location.
- Availability Zone (AZ): An availability zone (AZ) contains hosts sharing the same power system and a set of switches. Any two AZs cannot share data communication devices or power nodes in case of a natural disaster. Tenants are not recommended to arrange all data and hosts in one AZ. Otherwise, if the AZ encounters a power outage, all services will be interrupted. In an NFV solution, by default, assign an AZ to a DC.
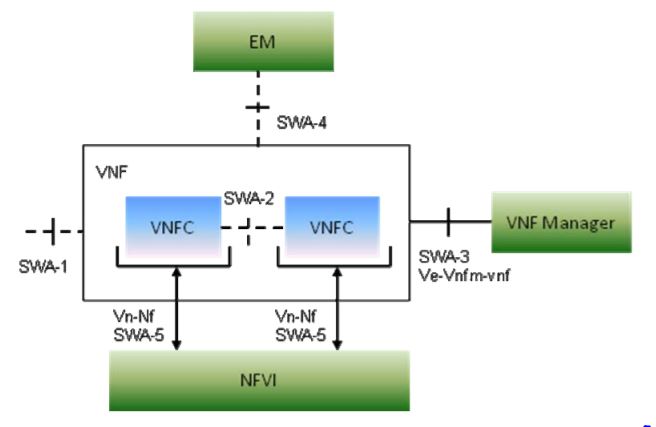
- VNFC: A virtualized network function component (VNFC) is an internal component of a VNF. It provides a VNF provider with a defined sub-set of that VNF’s functionality. A VNFC can be deployed on multiple VMs, or multiple VNFCs can share a VM.
- VNFP: A virtualized network function platform (VNFP) provides O&M interfaces, configuration interfaces, and manages devices.
- Hypervisor: Hypervisor is the software layer between physical servers and operating systems. It takes the role of the virtual machine monitor (VMM) and allows multiple operating systems and applications to share the hardware. Mainstream hypervisors include VMware’s vSphere, IBM’s PowerVM, and Red Hat’s Enterprise Virtualization, open-source KVM, Xen, and VirtualBSD.
- Host and Guest OS: A host OS is where the software is installed on a computer, which interacts with the underlying hardware and is usually used to describe an operating system used in a virtualized server. Whereas the guest OS which runs on a VM above the server.
- Boot OS: The boot OS is a minimal OS, similar to Windows BIOS. The boot OS provides basic file, disk, and network services for NPS VMs. The NPS and NLS can be started only after the guest OS is booted by using the boot OS. A boot OS is not required if carriers provide the guest OS.
- VM Flavour: Flavors define a number of parameters, including the CPU core quantity, memory size, storage capacity, CPU pinning, NUMA, high-precision, and hugepage, used to create a virtual machine. The OpenStack community defines five default flavors tiny, small, medium, large and extra large. VNFs can define different flavors through VNFD templates according to their own needs.
Related Posts: