Confusion Matrix – Machine Learning
Confusion Matrix
The confusion matrix is one of the best ways to evaluate the performance of a classification model in the Machine Learning. It allows to evaluate model’s performance, identify where it went wrong, and provide guidance on how can be fixed. This concept “confuse” the most people, particularly beginners who are just beginning with artificial intelligence or machine learning.
In this blog post, we will explain what a machine learning confusion matrix is, and how it can give you a detailed view of your model’s performance. Contrary to its name, a confusion matrix in machine learning is a powerful yet simple concept.
What is a Confusion Matrix?
A confusion matrix represents the accuracy of a classifier in a Machine Learning (ML). The confusion matrix displays the number true positives and true negatives. This matrix helps in analyzing the model performance, identifying incorrect classifications, and improving prediction accuracy.
A confusion matrix is a N x N matrix where N is total number of target categories. It compares actual target values to those predicted by the ML model. This allows us to get a comprehensive view of our classification model’s performance and the types of errors that it makes.
Following figure shown, a binary classification problem would require a matrix of 2 x 2,, which has 4 values.
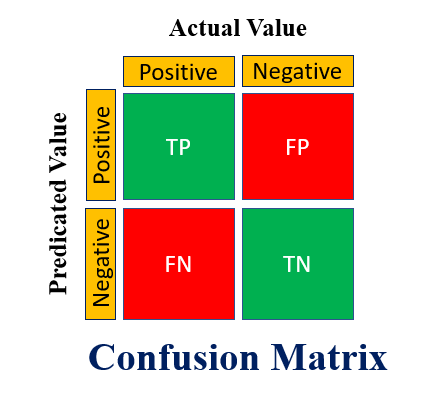
Terms used in Confusion Matrix
- True Positive : It indicates that the predicted value or class is the same as the actual value. The model predicted that the value would be positive.
- True Negative: It indicates that the predicted value or class is the same as the actual class. The model predicted that the value would be negative.
- False Positive (FP) – Type I Error: The value predicted was incorrect. The model predicted that the value would be positive, even though it was negative. It is also called the Type I error.
- False Negative (FN) – Type II Error: The value predicted was incorrect. The model predicted that the value would be negative, even though it was positive. It is also called the Type II error.
Confusion Matrix with Example
Let understand with an example. We have developed a Machine Learning Model for 5G System which can predict that when there can be crash or reboot of an gNodeB. Considering 10000 data points in a classification dataset. Following confusion matrix result show classifiers with a logistic regression algorithm or a decision trees.

- True Positive (TP) = 5600 means the model correctly classified 5600 positive class data points. In other words, model predicted 5600 time correctly there will be a crash
- True Negative (TN) = 3300 means the model correctly predicted or classified there is no crash
- False Positive (FP) = 600 means the model incorrectly predicted there is a crash, where there was actually no crash
- False Negative (FN) = 500 meaning the model incorrectly predicted there is no crash, where there was actually a crash
This can be considered a pretty decent Machine Learning Model, showing relatively larger no. of true positive and true negative values.
Why we need Confusion Matrix
Confusion matrix information helps to calculate ML Model performance in terms of Accuracy, Precision, Recall and F-1 score.
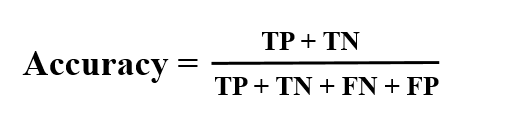
- ML Model Accuracy: Considering all the classes i.e. positive and negative, how many of them we have predicted correctly. Accuracy should be high as possible for a Machine Learning Model.
-
ML Model Precision: Considering all the classes, ML model have predicted as positive vs how many are actually positive. Precision of a ML Model should be high as possible.
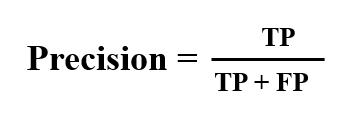
- ML Model Recall: Considering all the positive classes, how many we predicted correctly. Recall of a ML model should be high as possible.
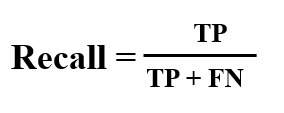
- ML Model F1-score: It helps to measure Recall and Precision at the same time. It uses Harmonic Mean in place of arithmetic Mean by punishing the extreme values more.

Scikit-learn Python Library for Confusion Matrix
Scikit-learn is a Python library we developer use it to develop the machine learning algorithms.It provides handy tools with easy-to-read syntax and build upon SciPy (Scientific Python) library.
It has two functions confusion_matrix() and classification_report() for Confusion Matrix use.
- Sklearn return confusion_matrix() the values of Confusion matrix. It is slightly different than what we’ve studied before. The rows are treated as actual values, and the columns are treated as predicted values. The rest of this concept is the same.
- Sklearn classification_report() outputs precision, recall, and f1-score for each target class. It also includes some additional values, including micro average; macro average and a weighted average.
Conclusion
This blog post should have given the reader a starting point on how to use and interpret a confusion matrix in machine learning algorithms. It is useful to understand where the model went wrong, and guide how to correct it. This matrix is commonly used to evaluate the performance and effectiveness of a machine learning classification model.
Related Post