What is RAG and How It Is Transforming Telecom Operations?
Large Language Models (LLMs) like GPT, Claude, and LLaMA are transforming the AI landscape, but they are trained on static datasets, which means they can’t access real-time or domain-specific knowledge unless they’re fine-tuned or retrained. Both fine-tuning and retraining are costly and time-consuming process.
To over come the above limitations, a Retrieval-Augmented Generation (RAG) an AI architecture is introduced. RAG combines powerful language models (LLMs) with external knowledge sources, allowing systems to generate more accurate, relevant, and up-to-date responses.
RAG Framework
The “RAG framework”, was introduced by Lewis. A basic methodology of a “Retrieval Augmented Generation (RAG)” system shows how it can improve the “capabilities of LLMs by grounding” their responses in real-time, related information. Whereas static models that generate responses based only on a fixed set of knowledge base, the RAG process includes the following key steps:
- Retrieval: Finds relevant information from a large database of texts.
- Augmentation: Adds this retrieved information to the given input for the generation model.
- Generation: Provides a response based on both the given input and the retrieved information.
This method ensures that the model can provide lasted and contextually accurate responses.
Why we need RAG?
RAG take care of inherent limitations of LLMs by improving accuracy, factual grounding, and scalability. It delivers more reliable, efficient, and scalable solutions compared to standalone LLMs. Following are the main reasons why we need RAG:
- Overcoming Static Knowledge: The knowledge within LLMs is fixed after training, making it inherently static. LLMs knowledge becomes outdated over time and cannot incorporate new or updated information without retraining. RAG dynamically retrieves real-time or external knowledge from latest sources e.g. knowledge bases, documents, or databases, enabling the model to access the latest information without retraining.
- Hallucinations: LLMs can produce outputs that are factually incorrect, irrelevant, or fabricated when they encounter unfamiliar or ambiguous queries. Hallucinations occur because LLMs generate outputs based on available patterns in provided training data rather than validated knowledge. By retrieving relevant facts or passages from trusted sources, RAG grounds the model’s output in factual information, significantly reducing hallucinations.
- Domain-Specific Knowledge Adaptation: General LLMs lack domain expertise: Pre-trained LLMs might not perform well in specialized domains e.g. telecom, financial, or legal contexts. RAG allows the model to retrieve domain-specific information on demand without requiring costly domain-specific retraining.
- Cost-Efficient Updates: Updating LLMs is expensive because training or fine-tuning large models to add new knowledge requires massive computational resources. With RAG To update knowledge, only the retrieval database needs to be refreshed. The model itself remains unchanged.
- Improved Long Context Management: LLMs have a limited context window, they struggle to handle extremely long documents or queries with multiple relevant sources. Using RAG it requires retrieving only the most relevant pieces of information, RAG reduces the burden on the context window and ensures the model focuses on key facts.
RAG Architecture
A generic architecture of “RAG system”, showing how it fundamentally works and “enhances the capabilities of LLMs” is illustrated in the following figure.
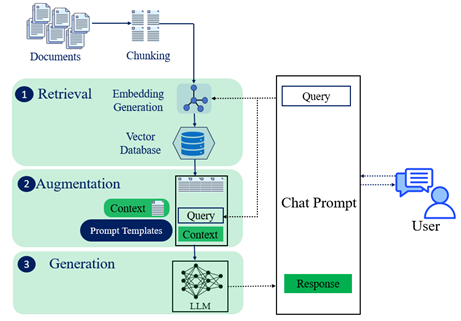
The complete working of RAG architecture can be explained in following steps.
- Document Collection: Start by gathering relevant text data from different sources like PDFs, text files or structured documents. This raw data is very critical for creating a knowledge base for the system to be used during retrieval.
- Text Cleaning and Chunking: Clean the text by removing noise and formatting it. Then, break it down into smaller pieces, like words or groups of words (tokens). This makes the retrieval process more efficient and accurate.
- Embeddings Generation: Convert the cleaned and segmented text into “vector representations using embedding models” such as “Sentence Transformers” or “BERT”. These vectors embeddings capture the meaning of the text and are stored in an optimized vector database for quick retrieval.
- Content Retrieval: When a user query is input, it’s transformed into a vector similar to the ones in the stored vector. The system searches the most relevant pieces of information related to the query in this database and retrieve, ensuring the response uses the latest information.
- Context Augmentation: When it combines “two knowledge streams”. “The fixed, general knowledge embedded vectors in the LLM and the flexible, domain-specific information retrieved on demand”. This enriches the context for the LLM.
- Generating Response: The augmented prompt which includes the user’s query combined with the retrieved information is fed into an LLM such as GPT, or Llama. “The LLM processes this input to generate a factually accurate and coherent response”.
- Final Output: The result is an enhanced output that minimizes the risk of errors or outdated information. It clearly links the response to real-world sources, providing relevant and accurate answers.
Use Cases of RAG in Telecom
- RAN Deployment via Internal Architecture Documents
- Problem: Engineers struggle to locate specific n/w deployment procedures from vast technical documents, often resulting in errors or deployment delays.
- RAG Solution: Retrieves detailed site-specific architecture diagrams, DU/CU parameters, and configuration steps from internal knowledge repositories and technical manuals.
- Impact: Faster and more accurate deployments, fewer errors, and real-time assistance for field teams without relying on SMEs.
- Network Operations & Fault Diagnosis
- Problem: Engineers face complex network logs and incident data.
- RAG Solution: Ingests logs, manuals, and SOPs to assist engineers in diagnosing faults by retrieving relevant cases and solutions.
- Impact: Reduce downtime and improve mean time to repair (MTTR)
- SLA Violation Analysis by Referencing Contracts and System Logs
- Problem: SLA violations are difficult to trace due to scattered data across legal contracts, system logs, and performance reports, requiring manual correlation by legal and operations teams.
- RAG Solution: Retrieves relevant SLA terms from contracts and correlates them with time-stamped system logs and KPI reports to assess if and when a violation occurred.
- Impact: Automated, transparent SLA violation analysis with reduced audit time and improved coordination between technical and legal departments.
- Field Technician Assistance
- Problem: Technicians may not recall every detail of equipment manuals or regional deployment variations.
- RAG Solution: Mobile RAG assistants retrieve location-specific installation guides or FAQs from the central document store.
- Impact: Increased accuracy and reduced onsite troubleshooting time.
- Intelligent Customer Support
- Problem: Legacy chatbots give generic or outdated responses.
- RAG Solution: Retrieves real-time data from internal knowledge bases (e.g., troubleshooting guides, billing policies) to provide accurate and context-aware responses.
- Impact: Improved first-call resolution, reduced agent handoffs, and increased customer satisfaction
- Automated RFP Response Generation Using Historical Tender Data
- Problem: Responding to RFPs is time-consuming and repetitive, often requiring teams to manually search through previous submissions and templates.
- RAG Solution: Retrieves relevant content from historical RFP responses and generates draft responses tailored to the current tender requirements.
- Impact: Accelerated proposal generation, increased consistency and compliance, and more time for sales teams to focus on strategic value propositions.
- Regulatory & Compliance Automation
- Problem: Telecom regulations differ across regions and evolve frequently.
- RAG Solution: Enables dynamic retrieval of the latest compliance requirements for licensing, data privacy, and spectrum usage.
- Impact: Ensures up-to-date adherence to legal standards with less manual effort.
- Knowledge Management & Internal Training
- Problem: Internal knowledge gets fragmented across wikis, PDFs, and emails.
- RAG Solution: Aggregates and retrieves information from multiple internal sources to answer employee queries or train new hires.
- Impact: More efficient onboarding and reduced dependency on SMEs.
- Sales & Plan Recommendations
- Problem: Recommending the right plan or device based on user needs is challenging.
- RAG Solution: Combines real-time CRM data with plan catalogs to recommend personalized offers via chat or IVR.
- Impact: Higher conversion rates and better user experience.
Conclusion
As telecom networks continue to evolve in complexity and scale, relying solely on static LLMs is no longer sufficient. Retrieval-Augmented Generation (RAG) bridges the gap by injecting real-time, domain-specific knowledge into generative models—making them smarter, more accurate, and far more useful in critical business functions.
Whether it’s improving network reliability, assisting field engineers, accelerating RFP responses, or delivering personalized customer experiences, RAG is unlocking a new wave of efficiency in telecom operations.
By adopting the RAG architecture, telecom providers not only reduce operational costs but also future-proof their AI capabilities in a fast-changing technological landscape. As the industry moves toward autonomous networks and AI-native infrastructure, RAG will be a foundational pillar in the journey.
Related Post
- Machine Learning – Supervised, Unsupervised and Reinforcement
- Machine Learning – Principal Component Analysis
- Confusion Matrix – Machine Learning
- Machine Learning – Principal Component Analysis
- Approaches of Applying Deep Learning in Physical Layer