What is NUMA (non-uniform memory access)?
Non-uniform memory access (NUMA)
In the past, processors had been designed as Symmetric Multi-processing or Uniform Memory Architecture (UMA) machines, which mean that all processors shared the access to all memory available in the system over the single bus. Now days, with tons of data compute applications, memory access speed requirement is increased, and in UMA machines, due to accessing the memory by multiple CPUs over a single bus, there is more load on the shared bus and due to limited bus bandwidth, there are challenges like latency and collisions between multiple CPUs.
This era of data centric processing with huge requirement of speed between CPU and memory, gave birth to a new architecture called Non-uniform memory access (NUMA) or more correctly Cache-Coherent Numa (ccNUMA). In this architecture each processor has a local bank of memory, to which it has a much closer (lower latency) access. Mean, we divide the complete available memory to each individual CPU, which will become their own local memory. In case, any CPU wants more memory, it can still access memory from other CPU, but with little higher latency.

Today, processors are so fast that they usually require memory to be directly attached to the socket that they are on. So memory accesses from a single processor to local memory not only have lower latency compared to remote memory accesses but do not cause contention on the interconnect and the remote memory controllers.
However, there can be a small group of CPUs accessing their own local memory all together. So there can be several such groups of CPUs and memory, known as NUMA Nodes.
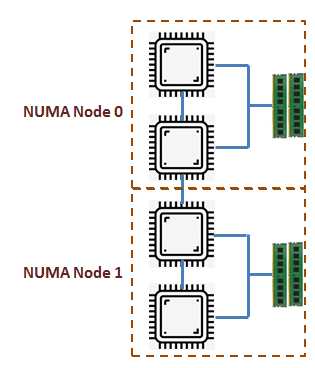
Few NUMA Features
- To compensate for memory latency effects due to some memory being closer to the processor than others.
- Useful to scale the VM for large amounts of memory
- I/O optimizations due to device NUMA effects


