LLMs vs SLMs: A Comparative Analysis
Introduction
Artificial Intelligence has evolved over the years and language models are becoming a transformative technologies across different industries. Starting from chatbots and coding assistants to document summarization and task automation, language models are changing how humans interact with the machines.
While Large Language Models (LLMs) such as GPT-4, Claude, Gemini, and Llama 3 have dominated the industry, a new category is emerging known as Small Language Models (SLMs) . SMLs are compact models offer impressive performance while needs significantly low compute resources.
This article provides a comprehensive comparison of LLMs vs SLMs, covering architecture, capabilities, performance, cost, deployment, and real-world applications.
LLM vs SLM in Details Explanation
Large Language Model (LLM): A LLM is a deep neural network trained on enormous datasets containing books, articles, websites, source code, and conversations. LLMs typically contain billions to trillions of parameters, enabling them to understand context, reason across multiple topics, generate human-like text, and perform a wide range of language tasks. LLM examples includes such as GPT family, Claude, Gemini, Llama and DeepSeek
Key Characteristics
- Massive parameter count (7B–1T+)
- Trained on internet scale datasets
- Excellent context understanding
- Strong reasoning capabilities
- Supports multiple tasks without retraining
- Usually deployed in a cloud infrastructure
Small Language Model (SLM): A SLM is a compact AI model designed to perform language tasks using significantly fewer parameters. Rather than competing directly with LLMs in raw intelligence, SLMs focus on Speed, Efficiency, Lower hardware requirements, Edge deployment and Domain specialization.
SLMs generally range from hundreds of millions to a few billion parameters. Many SLMs can run on devices like Smartphones, Laptops, IoT devices, Embedded systems and Industrial edge hardware
LLM and SLM Key Differentiator
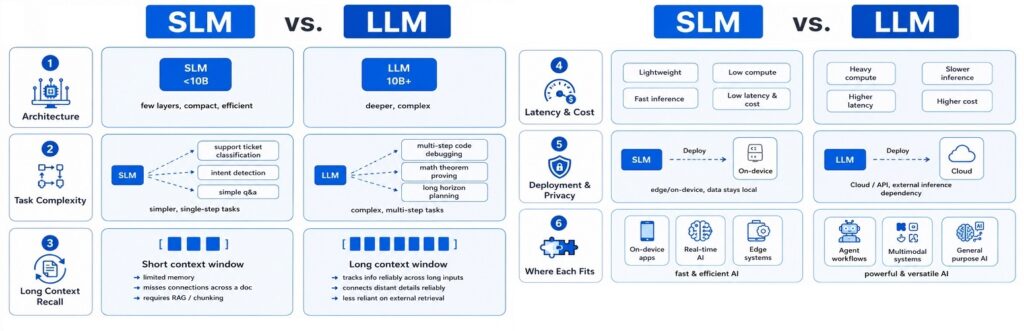
- Architecture: SLMs are usually under 10B parameters and run on a laptop or phone. LLMs sit at 10B+ with deeper layers and more attention heads, built for broad reasoning across tasks.
- Task Complexity: SLMs work well on simple tasks but fail on complex multiple reasoning steps. LLMs handle difficult math, multi-step code, and long-horizon planning.
- Long Context Recall: SLMs lose the thread across long documents or extended conversations. LLMs reliably track and connect information across large inputs.
- Latency and Cost: SLMs run on consumer hardware with low response times and significantly lower inference costs. LLMs require GPU and carry higher costs per request.
- Deployment and Privacy: SLMs run on-device or on-premise. LLMs are typically cloud-hosted, which adds data governance complexity.
- Where each fits:
- SLMs: on-device assistants, real-time classification, or privacy-sensitive applications
- LLMs: complex reasoning, agent workflows, or broad knowledge tasks.
LLM and SLM Comparison Table
| Feature | Large Language Models (LLMs) | Small Language Models (SLMs) |
|---|---|---|
| Typical Parameter Size | 7B–1T+ parameters | 100M–7B parameters |
| Training Dataset | Internet-scale datasets (trillions of tokens) | Curated or domain-specific datasets |
| Model Size | Several GB to hundreds of GB | Hundreds of MB to a few GB |
| Inference Speed | Slower | Fast with low latency |
| Accuracy | Excellent across diverse tasks | High for specialized tasks |
| Reasoning Capability | Strong multi-step reasoning | Moderate reasoning ability |
| Context Window | 32K–1M+ tokens | 4K–32K tokens |
| Hardware Requirement | High-end GPUs / AI Accelerators | CPU, Laptop, Smartphone, Edge Devices |
| Deployment | Cloud / Data Center | On-device / Edge / Private Cloud |
| Internet Connectivity | Usually Required | Optional |
| Latency | Higher | Very Low |
| Power Consumption | High | Low |
| Operational Cost | High | Low |
| Privacy | Lower (Cloud Processing) | Higher (On-device Processing) |
| Offline Capability | Limited | Excellent |
| Fine-tuning | Expensive | Easier & Cost-effective |
New Technology Trends for LLMs and SLMs
The future of AI is unlikely to be depended on LLMs. Instead, a shift toward hybrid AI systems has been observed where LLMs and SLMs complement each other. Key trends include:
- Distillation: Knowledge distillation transfers the intelligence of a large language model (teacher) to a smaller model (student). This enables SLMs to achieve good performance while requiring less memory, compute, and power.
- Retrieval-Augmented Generation (RAG): RAG enhances language models by retrieving relevant information from external knowledge bases before generating a response. This improves factual accuracy, reduces hallucinations, and keeps responses up to date.
- Mixture of Experts (MoE): MoE divides a large model into specialized expert networks and activates only the most relevant experts for each task. This improves computational efficiency while maintaining high performance.
- Edge AI: Edge AI runs language models directly on devices such as smartphones, IoT devices, vehicles, and industrial systems. It enables low-latency inference, offline operation, and better data privacy.
- Federated Learning: Federated Learning trains AI models across multiple devices without transferring raw data to a central server. This preserves user privacy while allowing the model to continuously improve through distributed learning.
FAQs
Q1. What is the main difference between LLMs and SLMs?
Answer: LLMs have billions or trillions of parameters and provide better reasoning and general-purpose capabilities, while SLMs use much lesser parameters to deliver faster, more efficient, and low-cost inference.
Q2. Can SLMs run without an internet connection?
Answer: Yes, Many SLMs are designed for on device deployment and can run offline or without internet on laptops, smartphones, or an embedded hardware.
Q3. Are SLMs less accurate than LLMs?
Answer: For complex detailed reasoning and broad knowledge tasks, LLMs generally perform better than SLMs. However, SLMs can achieve excellent accuracy in focused, domain specific applications.
Q4. Which is better for edge computing?
Answer: SLMs are more suitable for edge computing because they require less memory, lower power, and can provide real-time responses on resource limited devices.
Q5. Can LLMs and SLMs be used together?
Answer: Yes. Many modern AI systems use hybrid architectures approach, where an SLM handles local or routine tasks and an LLM is invoked for more complex reasoning, enabling a balance of performance, cost, and privacy.